Abstract
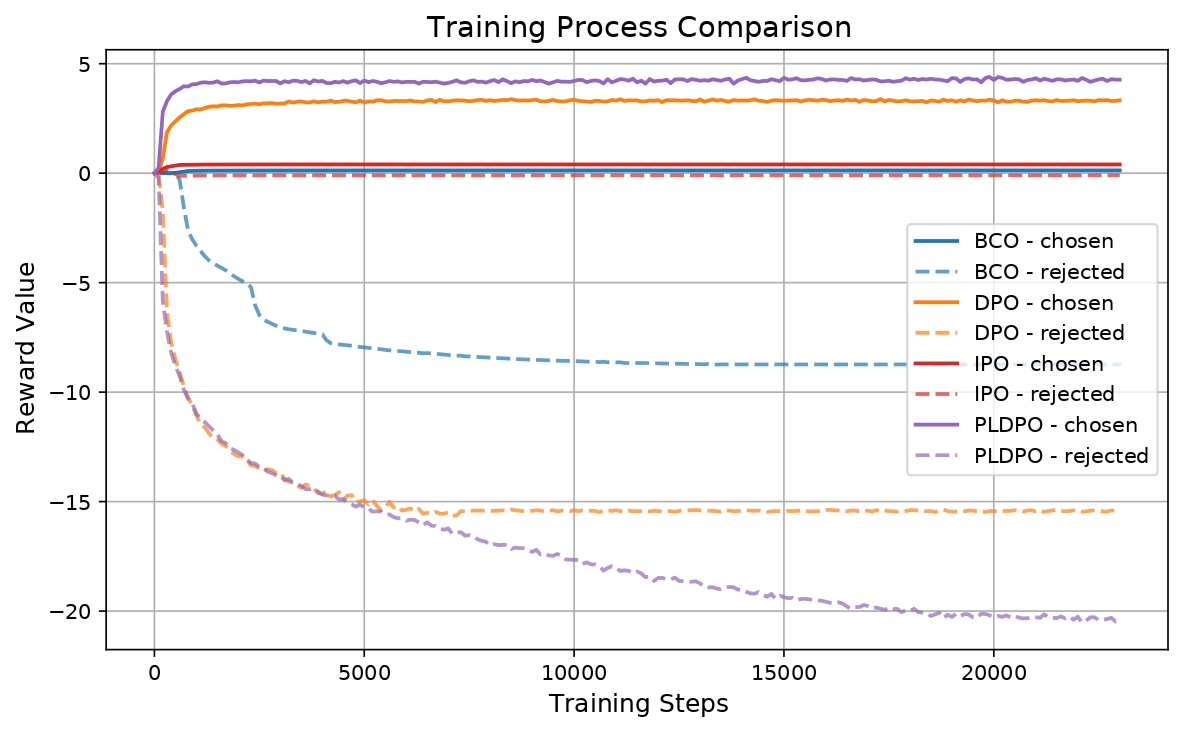
This paper introduces Multi-PrefDrive, a framework that significantly enhances LLM-based autonomous driving through multidimensional preference tuning. Aligning LLMs with human driving preferences is crucial yet challenging, as driving scenarios involve complex decisions where multiple incorrect actions can correspond to a single correct choice. Traditional binary preference tuning fails to capture this complexity. Our approach pairs each chosen action with multiple rejected alternatives, better reflecting real-world driving decisions. By implementing the Plackett-Luce preference model, we enable nuanced ranking of actions across the spectrum of possible errors. Experiments in the CARLA simulator demonstrate that our algorithm achieves an 11.0% improvement in overall score and an 83.6% reduction in infrastructure collisions, while showing perfect compliance with traffic signals in certain environments. Comparative analysis against DPO and its variants reveals that Multi-PrefDrive's superior discrimination between chosen and rejected actions, which achieving a margin value of 25, and such ability has been directly translates to enhanced driving performance. We implement memory-efficient techniques including LoRA and 4-bit quantization to enable deployment on consumer-grade hardware and will open-source our training code and multi-rejected dataset to advance research in LLM-based autonomous driving systems.
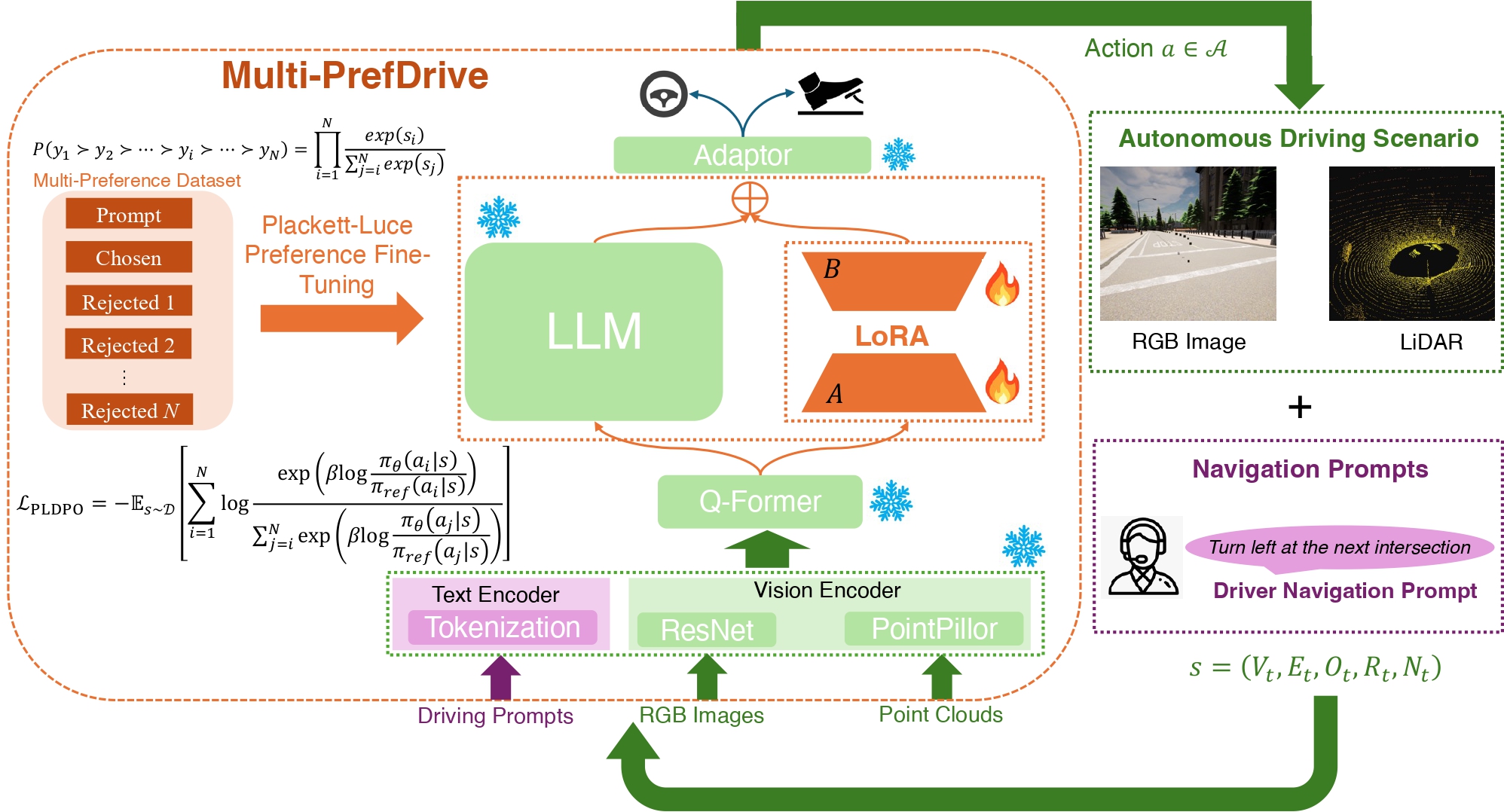
Multi-PrefDrive Framework
Experiments
| Method | Overall | Safety | Navigation | Infrastructure | Red Light | Route | Vehicle |
|---|---|---|---|---|---|---|---|
| Score (↑) | Metric (↑) | Score (↑) | Collisions (↓) | Infractions (↓) | Deviation (↓) | Blocked (↓) | |
| Town 01 | |||||||
| LMDrive (baseline) | 53.00 | 0.86 | 59.10 | 0.73 | 0.22 | 1.32 | 0.11 |
| DPO | 56.12 (↑5.9%) | 0.88 (↑2.3%) | 64.15 (↑8.5%) | 0.27 (↓63.5%) | 0.16 (↓28.1%) | 1.36 (↑3.0%) | 0.00 (↓100.0%) |
| NoPrefDPO | 51.45 (↓2.9%) | 0.91 (↑5.8%) | 55.17 (↓6.7%) | 0.61 (↓17.0%) | 0.20 (↓11.9%) | 1.74 (↑31.7%) | 0.08 (↓25.0%) |
| BCO | 54.48 (↑2.8%) | 0.91 (↑5.8%) | 59.42 (↑0.5%) | 0.25 (↓65.8%) | 0.20 (↓8.7%) | 1.60 (↑21.4%) | 0.00 (↓100.0%) |
| IPO | 52.93 (↓0.1%) | 0.91 (↑5.8%) | 56.87 (↓3.8%) | 0.47 (↓35.0%) | 0.15 (↓31.6%) | 1.78 (↑34.9%) | 0.11 (0.0%) |
| PLDPO | 58.85 (↑11.0%) | 0.92 (↑7.0%) | 63.59 (↑7.6%) | 0.12 (↓83.6%) | 0.15 (↓32.3%) | 1.15 (↓12.9%) | 0.00 (↓100.0%) |
| Town 04 | |||||||
| LMDrive (baseline) | 60.11 | 0.93 | 65.25 | 0.00 | 0.24 | 1.86 | 0.00 |
| DPO | 62.81 (↑4.5%) | 0.95 (↑2.2%) | 67.59 (↑3.6%) | 0.00 (0.0%) | 0.12 (↓49.3%) | 1.84 (↓0.7%) | 0.00 (0.0%) |
| NoPrefDPO | 62.27 (↑3.6%) | 0.94 (↑1.1%) | 68.35 (↑4.7%) | 0.00 (0.0%) | 0.05 (↓80.1%) | 1.77 (↓4.6%) | 0.00 (0.0%) |
| BCO | 57.63 (↓4.1%) | 0.94 (↑1.1%) | 62.17 (↓4.7%) | 0.00 (0.0%) | 0.19 (↓17.9%) | 1.86 (0.0%) | 0.00 (0.0%) |
| IPO | 62.12 (↑3.3%) | 0.94 (↑1.1%) | 67.34 (↑3.2%) | 0.00 (0.0%) | 0.08 (↓65.8%) | 1.76 (↓5.0%) | 0.00 (0.0%) |
| PLDPO | 63.69 (↑6.0%) | 0.95 (↑2.2%) | 68.35 (↑4.7%) | 0.00 (0.0%) | 0.00 (↓100.0%) | 1.75 (↓5.5%) | 0.00 (0.0%) |
| Parameter | Value |
|---|---|
| Base Model | LLaMA-7B |
| Training Strategy | LoRA |
| LoRA Rank (r) | 16 |
| LoRA Alpha (α) | 16 |
| Learning Rate | 1e-5 |
| Batch Size | Auto-calculated based on GPU memory |
| Gradient Accumulation Steps | max(1, 32 // batch_size) |
| Training Epochs | 3 |
| Maximum Sequence Length | 2,048 |
| Warmup Ratio | 0.1 |
| Max Gradient Norm | 0.3 |
| DPO β | Scheduled (0.05-0.2) |
| LoRA Target Modules | |
| q_proj, k_proj, v_proj, o_proj, gate_proj, down_proj, up_proj | |
Conclusion
Our work with Multi-PrefDrive advances autonomous driving systems by addressing a fundamental limitation in preference learning approaches. By recognizing that real-world driving scenarios present numerous potential errors of varying severity rather than simple binary choices, we've developed a framework that captures this complexity through multi-rejected preference tuning. The experimental results demonstrate that our PLDPO approach outperforms conventional DPO variants with significant improvements in safety-critical metrics, and achieving perfect compliance with traffic rules in certain scenarios. The clear correlation between the larger preference margins learned during training and improved driving performance validates our approach's theoretical foundations. Moreover, through memory-efficient implementation techniques, we've made this sophisticated preference learning accessible to researchers without expensive hardware, and our forthcoming open-source code and multi-rejected dataset will enable broader exploration of this promising direction. As autonomous driving systems continue to advance, we believe multi-dimensional preference learning will be crucial for developing vehicles that can navigate complex urban environments with human-like judgment and safety prioritization.